

Have you ever struggled when managing contributor identities within software projects? GrimoireLab is developing a new SortingHat version, the tool used for identity management, to turn it into a GraphQL service! This article summarizes how we used Graphene, a library for building GraphQL APIs in Python, for boosting SortingHat’s integration with other apps.
People contributing to software projects interact with the them through many different channels, such as ticket/issues systems, Q&A forums, chats, mailing lists, code review, social media or meetings and events
From a project management perspective, a person needs to know their community. In order to get valuable insights, that person may end up asking two main questions:
- How many contributors does the project has?
- How many organizations are contributing to the project?
To answer these questions, we need to manage contributor identities within the project. Let’s clarify this scenario using two contributors:
But wait… it turns out they are the same person! For those people knowing this contributor in person, this may not be a surprise, but a project manager may not have this information all the time. If this happens, this person would have been identified as different contributors and the metrics analyzed for the project would be incorrect.
In real life, this can be “a little bit” more complex:

At this point, some people may get crazy wondering who is who in the project. This is the reason why SortingHat is for, the GrimoireLab tool for managing contributor identities.
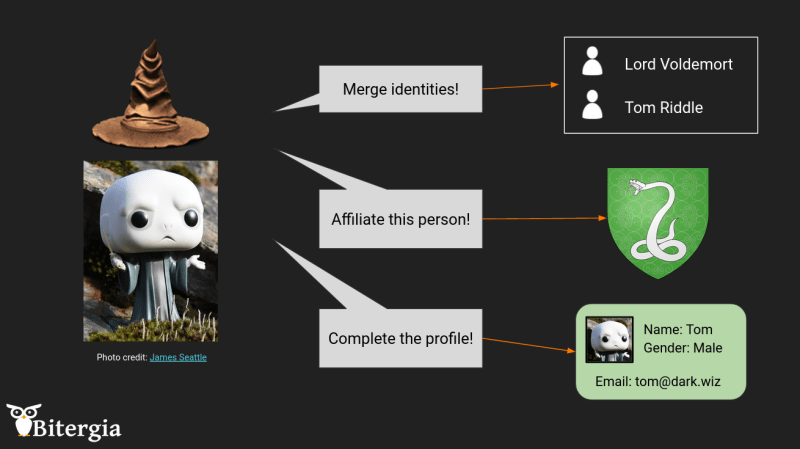
SortingHat allows to perform base operations for managing many entities related with identities management (identities, organizations, enrollments, profiles, etc.). For instance, going back to the example we set above, we could ask SortingHat to merge those identities, add a new affiliation and complete that person’s profile with some basic information.
Boosting SortingHat integration
Now that we have dived into SortingHat some of its capabilities, it is time to talk about integration. Until now, SortingHat could be accessed via command line, imported as a Python module and also via Hatstall, a web-UI.
How can we boost integration? We started with the main idea of building a robust API. This API would have to be flexible and easy to adapt and ensure consistency as we expect it to be heavily used (i.e., many users and applications at the same time). That’s when GraphQL comes into play!
Why following this approach to build the API?
Let’s imagine we want to get a view for our application showing the information for a given unique identity. We may want to show its individual identities, its profile, its enrollments and the main email domains for each organization where it is enrolled.
If we followed a traditional REST approach, we would need to access to different endpoints to get the information we need for this view:
/unique_identities/<uuid>/identities /unique_identities/<uuid>/profile /unique_identities/<uuid>/enrollments /organizations/<org_name>/domains
However, REST approach have some pitfalls to highlight:
- It needs multiple requests per view (see example above).
- The structure is just a convention between the server and the client.
- It is common to ask for more information than is needed (overfetching) and also the opposite (underfetching).
- The API documentation is not tied to the development.
Let’s see how a GraphQL query would look like for getting the information for the same view:
query { unique_identities(uuid:“<uuid>”) { identities { uid } profile { email gender } enrollments { organization end_date } domains { domain_name } } }
Pointing out some of the strongest pros of using a GraphQL approach for building the API:
- It needs one single request per view.
- The client defines what it receives and the server only sends what is needed.
- It is a strongly-typed language, which enforces field validation.
Turning SortingHat into a GraphQL service
At Bitergia, main maintainers from GrimoireLab tool, we are working to turning SortingHat into a service (currently under development). It is based on Graphene, a Python module that provides tools to implement a GraphQL API in Python. We are also working with Graphene-Django, another Python module built on top of Graphene which provides additional abstractions from Django framework.
The first step to take when designing a GraphQL service is to define its schema, which describes what data can be queried. We need to define three basic parts:
- Types: Which are the data types we are using in the service.
- Queries: What data we can ask for and how it is returned.
- Mutations: Operations modifying the data.
In Graphene-Django, these parts are correspondingly defined using Django abstractions:
- The types are defined by models.
- For the queries, we need to implement resolvers.
- The mutations can be translated as CRUD operations.
About the data types, we need to define our data model. If we have a look at the example we saw before, its structure is already very similar to a graph. We have defined types for all the basic entities we have in SortingHat (unique identities, single identities, organizations, domains, enrollments, profiles, and more).

Next, is to define some queries. Let’s see a recipe for building a basic query asking for the existing organizations.
Step 1
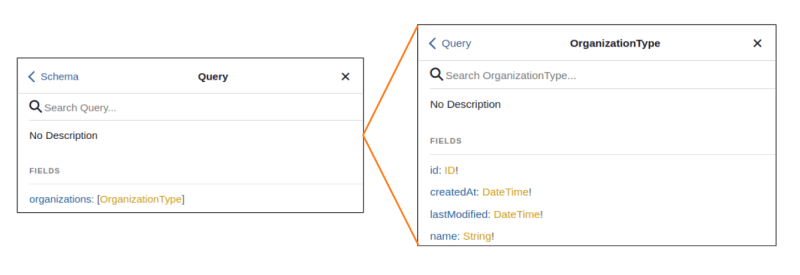
Define a new model object, in this case for Organizations. Then, we define a new type in schema.py script and define a basic resolver for the new query which returns all the Organization objects.

Once the query is defined, we will see that the API documentation has been automatically updated!
Step 2
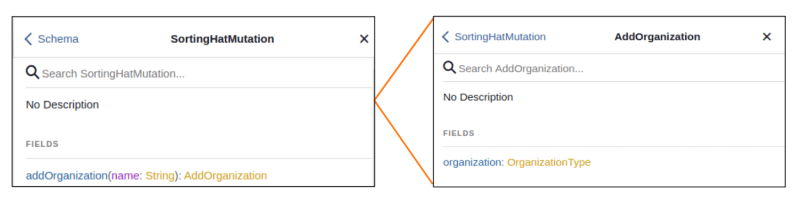
Now that we have defined a basic type, we can define a new mutation and the fields we are going to accept as input. In this example, we are creating a mutation for adding a new organization. This means we need one field, in this case is the name of the organization to be added. Then, in the mutation class we specify which internal method is performing this change into the database.

This mutation is calling an internal method called add_organization, which is inside the api.py module. This module controls basic exceptions and calls to the corresponding method modifying the database directly, named db.py.

And, once again, we can see the API documentation has been automatically updated.
Closing remarks and future work
We have covered the main requirements to implement GraphQL in SortingHat. We also worked on extra features, such as pagination or authentication, that we will explain as a second part of this module. Meanwhile, you can find more detailed information at my talk in FOSDEM 2020.
Among the several features we are adding to this new version of SortingHat, one of the most important thing is implementing a command line and web client for this new service, plus checking what happens with nested queries and how to set a limit.
I am a Software Engineer working at Bitergia, a software development analytics firm composed by the main maintainers of GrimoireLab software which is also part of CHAOSS, one of the projects hosted at The Linux Foundation.
If you would like to contribute to this Open Source project, feel free to join GrimoireLab community. Of course, feedback is more than welcome!







