
With more than 30 data sources supported, Perceval is one of the key GrimoireLab‘s components to get software project data in Bitergia Analytics. Let’s meet it…
Over the years, platforms like GitHub, StackOverflow, and even Slack or Meetup have became important tools to support, coordinate and promote the daily activities around software development. This is specially true for Open Source projects, which rely heavily on distributed and collaborative development.
Beyond being successfully and increasingly adopted by both end-users and development teams, these tools offer relevant information, which can be analyzed to describe, predict, and improve specific aspects of software development projects.
However, accessing and gathering these data is often a time-consuming and an error-prone task, that entails many considerations and technical expertise. It may require to understand how to obtain OAuth tokens (e.g., StackExchange, GitHub) or prepare storage to download the data (e.g., Git repositories, mailing list archives); when dealing with development support tools that expose their data via APIs, special attention has to be paid to the terms of service (e.g., an excessive number of requests could lead to temporary or permanent bans); recovery solutions to tackle connection problems when fetching remote data should also taken into account; storing the data already received and retrying failed API calls may speed up the overall gathering process and reduce the risk of corrupted data.
Nonetheless, even if these problems are known, many scholars and practitioners tend to re-invent the wheel by retrieving the data themselves with ad-hoc scripts.
Meeting Perceval
Perceval is a tool that simplifies the collection of project data by covering the most popular tools and platforms related to contributing to Open Source development, thus enabling the definition of software analytics. I’s the evolution of tools that have been already used in academic research for more than 10 years and early Bitergia days, such as CVSAnalY, MailingListStats and Bicho.
Perceval is an industry-strength tool, that:
- allows to retrieve data from multiple sources in an easy and consistent way,
- offers the results in a the flexible JSON format,
- gives the possibility to connect the results with analysis and/or visualization tools.
Furthermore, it is easy to extend, allows cross-cutting analysis and provides incremental support (useful when analyzing large software projects). Check a video showcasing its main features:
Overview
Perceval was designed with a principle in mind: do one thing, and do it well. Its goal is to fetch data from data source repositories efficiently. It does not store nor analyze data, leaving these tasks to other specific tools.
Though it was conceived as a command line tool, it may be used as a Python library as well. It was named after Perceval (Percival or Parsifal in different translations), one of the knights of King Arthur and a member of the Round Table, who after suffering pains and living adventures was able to find the Holy Grail.
Currently, Perceval supports the following data sources:
- Version control systems: Git
- Source code review systems: Gerrit, GitHub.
- Bugs/Ticketing tools: Bugzilla, GitHub, JIRA, Launchpad, Phabricator, Redmine
- Mailing: Hyperkitty, MBox archives, NNTP, Pipermail
- News: RSS, NNTP
- Instant messaging: Slack, Supybot archives (IRC), Telegram
- Questions & Answers sites: Askbot, Discourse, StackExchange
- Documentation: Confluence, Mediawiki
- Others: DockerHub, Jenkins, Meetup
A common execution of Perceval consists of fetching a collection of homogeneous items from a given data source. For instance, issue reports are the items extracted from Bugzilla and GitHub issues trackers, while commits and code reviews are items obtained from Git and Gerrit repositories.
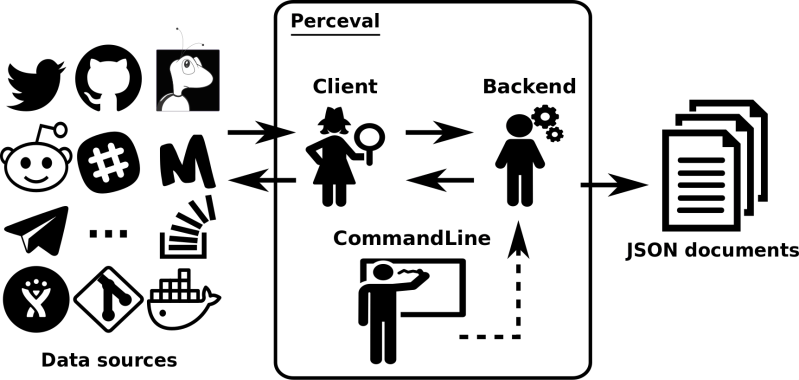
Each item is inflated with item-related information (e.g., comments and authors of a GitHub issue) and metadata useful for debugging (e.g., back-end version and timestamp of the execution). The output of the execution is a list of JSON documents (one per item). The overall view of Perceval’s approach is summarized in Figure 1. At its heart there are three components: Backend, Client and CommandLine.
Backend
The Backend orchestrates the gathering process for a specific data source and puts in place incremental and caching mechanisms. Backends share common features, such as incrementality and caching, and define also specific ones tailored to the data source they are targeting.
For instance, the GitHub back-end requires an API token and the names of the repository and owner; instead the StackExchange back-end needs an API token plus the tag to filter questions.
Client
The backend delegates the complexities to query the data source to the Client. Similarly to backends, clients shares common features such as handling possible connection problems with remote data sources, and define specific ones when needed.
For instance, long list of results fetched from GitHub and StackExchange APIs are delivered in pages (e.g., pagination), thus the corresponding clients have to take care of this technicality.
CommandLine
The CommandLine allows to set up the parameters controlling the features of a given backend. Furthermore, it also provides optional arguments such as help and debug to list the backend features and enable debug mode execution, respectively.
Perceval in action
You can install Perceval from Python packages:
$ pip3 install perceval
Or from from source code
$ git clone https://github.com/chaoss/grimoirelab-perceval.git
$ pip3 install -r requirements.txt
$ python3 setup.py install
Or you can use even a Docker image. Further installation information can be found in the Perceval GitHub repository.
Perceval is being developed and tested mainly on GNU/Linux platforms. Thus, it is very likely it will work out of the box on any Linux-like (or Unix-like) platform, upon providing the right version of Python available.
Once installed, a Perceval backend can be used as a stand-alone program or Python library. We showcase these two types of executions by fetching data from a Git repository.
Stand-alone Program
Using Perceval as stand-alone program does not require much effort, but only some basic knowledge of GNU/Linux shell commands.
$ perceval git https://github.com/chaoss/grimoirelab-perceval > /perceval
Sir Perceval is on his quest.
Fetching commits: 'https://github.com/chaoss/grimoirelab-perceval' git repository from 1970 -01 -01 00:00:00+00:00; all branches
Fetch process completed:
1170 commits fetched
Sir Perceval completed his quest.
The listing above shows how easy it is to fetch commit information from a Git repository. As can be seen, the backend for Git requires the URL where the repository is located, then the JSON documents produced are redirected to the file perceval.test. The remaining messages in the listing are prompted to the user during the execution. One interesting optional argument is the from-date, which allows to fetch commits from a given date, thus showing an example of how incremental support is easily achieved in Perceval.
Python Library
Perceval’s functionalities can be embedded in Python scripts. Again, the effort of using Perceval is minimum. In this case the user only needs some knowledge of Python scripting.
#!/usr/bin/env python3
from perceval.backends.core.git import Git
# URL for the git repo to analyze
repo_url = 'https://github.com/chaoss/grimoirelab-perceval'
# directory for letting Perceval clone the git repo
repo_dir = '/tmp/perceval.git '
# Git object, pointing to repo_url and repo_dir for cloning
repo = Git (uri=repo_url, gitpath=repo_dir)
# fetch all commits and print each author
for commit in repo.fetch():
print(commit['data']['Author'])
The listing above shows how to use Perceval in a script. The perceval.backends module is imported at the beginning of the file, then the repo_url and repo_dir variables are set to the URL of the Git repository and the local path where to clone it. These variables are used to initialize an object of the perceval.backends.git.Git class. In the last two lines of the script, the commits are retrieved using the method fetch and the names of their authors printed.
The fetch method, which is available in all backends, needs to be tailored to the target data source. Therefore, the Git backend fetches commits, while GitHub fetches issues/pull requests, StackExchange fetches questions, etc.
Data consumption
The JSON documents obtained by Perceval can be exploited by storing them to a persistent storage, such as an ElasticSearch database.
ElasticSearch provides a REST API, which works by marshaling data as JSON documents, using simple HTTP requests for communication.
Data in ElasticSearch are organized in indexes, which are collection of documents and document properties. Such data can be accessed using built-in modules (e.g., elasticsearch_dsl) and simple off-the-shelf tools (e.g., curl or Python libraries such as urllib or Requests), thus granting non-experienced users with comfortable access through its REST API. Then, the data can be processed with common libraries used in data analytics like Pandas and R, or visualized by Kibana dashboards.
Try it, fork it, and join the community
Perceval is one of the GrimoireLab tools, probably the most important one in terms of gathering data, and you are free to try it, fork it, and submit issues or send pull requests and ideas!







